 Бесплатный аудит сайта
Бесплатный аудит сайта



Файл robots.txt является важной частью любого веб-сайта. Этот файл используется для управления доступом к страницам сайта для поисковых роботов. Если сайт имеет файл robots.txt, то поисковые системы сначала прочтут его, чтобы узнать, какие страницы следует индексировать, а какие нет.
Что такое файл robots.txt
Файл robots.txt – это текстовый файл, расположенный в корневом каталоге веб-сайта, который сообщает поисковым роботам, какие страницы сайта должны индексироваться, а какие – нет. Этот файл не может запретить доступ к странице, но он может указать на то, что страницу не следует индексировать поисковыми системами.
Структура файла robots.txt
Файл robots.txt имеет следующую структуру:

Первая строка определяет поисковых роботов, для которых применяются следующие инструкции. Знак * означает, что инструкции будут действовать для всех поисковых роботов.
Вторая строка указывает, какие каталоги сайта не должны индексироваться. В примере выше поисковым роботам запрещается индексировать все страницы, находящиеся в директории /directory/.
Третья строка указывает на конкретный файл, который не должен индексироваться. В данном случае это файл file.html.
Пример файла robots.txt
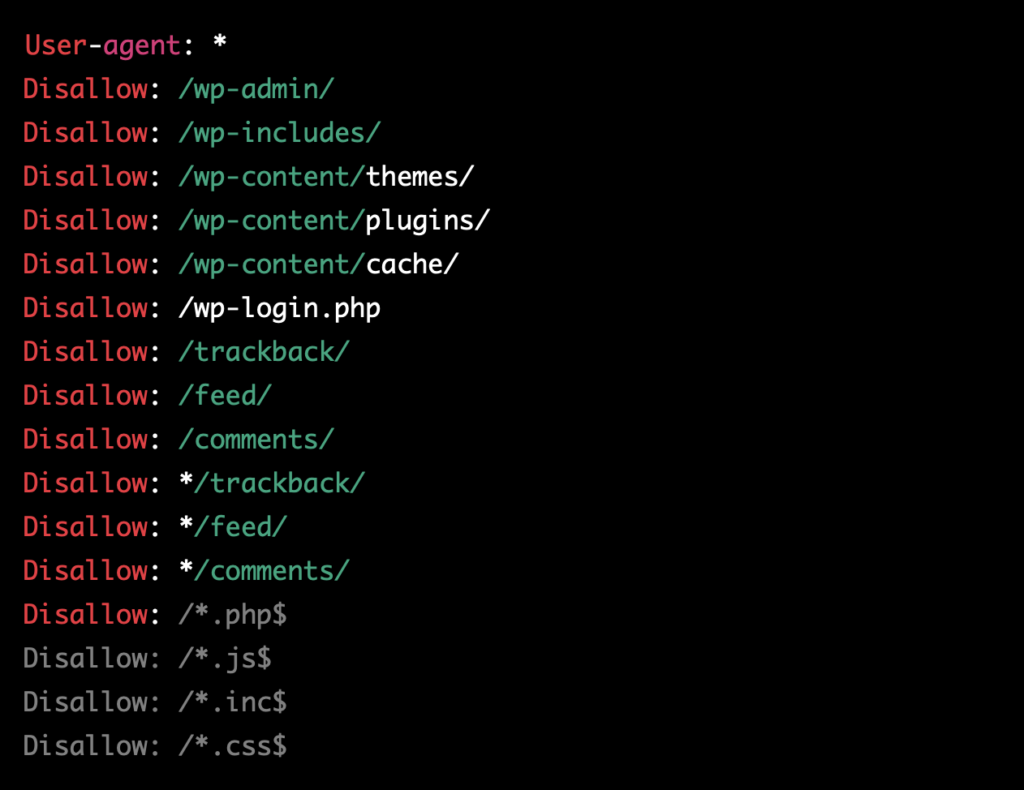
В этом примере файл robots.txt указывает на то, что все страницы, которые содержат в адресе /wp-admin/, /wp-includes/, /wp-content/themes/, /wp-content/plugins/, /wp-content/cache/, /wp-login.php, /trackback/, /feed/ и /comments/ не должны индексироваться. Также указаны запреты на страницы, содержащие в адресе строки, оканчивающиеся на .php, .js, .inc и .css.
Файл robots.txt для wordpress
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ru
Важные моменты при составлении файла robots.txt
Важно помнить о том, что чем меньше мусорных страниц, тем выше скорость индексации основных (важных) страниц вашего сайта. Поэтому если вы избавитесь от всего мусора, то индексация всех новых страниц, статей, записей, карточек товаров значительно ускорится, и ваш сайт, возможно, даже поднимется в поисковой выдаче за счет попадания большего количества целевых страниц в поисковую выдачу.
Важно также в файле robots.txt прописать главное зеркало и ссылку на xml-карту сайта (sitemap), потому что это поможет многократно улучшить индексацию вашего сайта!
Естественно, что составить файл надо правильно: после того как вы составили файл robots.txt, нужно зайти в панель «Вебмастера» Яндекса или «Гугла» и проверить, индексируется ли ваш сайт (все основные страницы, например главная страница, рубрики, каталог товаров, статьи и так далее). Кроме того, вы должны здесь же (в «Вебмастере») проверить, что вы запретили индексацию всех мусорных страниц.
Если же какие-то поисковые боты (например, от поиска mail.ru) нагружают ваш сервер, делают тысячи ненужных вам переходов по страницам вашего сайта, но пользователи из этих поисковых систем приходят на ваш сайт редко, то можете запретить вообще индексацию для всех поисковых роботов, кроме Yandex и Google. Но это делать нужно только в крайнем случае, например чтобы защититься от парсинга собственного сайта, или если нагрузка на хостинг достигает критических отметок.
Так как этот файл очень важен, то постарайтесь максимально подробно изучить структуру его составления, чтобы нужные вам страницы остались в выдаче поисковых систем, а не были заблокированы из-за того, что вы допустили какую-то ошибку.
Помните также, что составление robots.txt зависит также и от того, на каком движке (CMS) работает ваш сайт. Например, для блога на WordPress файл robots.txt будет значительно отличаться от того же файла для интернет-магазина на движке «1С-Битрикс».
Зачем нужен файл robots.txt
Самое главное, зачем составляют файл robots.txt — это более быстрая и полная индексация вашего сайта! Все дело в том, что в большинстве случаев на сайте существуют различные страницы, которые не должны попадать в индекс Яндекса и Google, но которые открыты для индексирования, и поисковым ботам ничего не остается, кроме как сканировать все эти страницы.
Вот пример подобных страниц, которые оказывают негативное влияние на индексацию всего вашего сайта в целом:
- Дубликаты страниц (например, это может быть одна и та же страница на вашем сайте, но доступная под разными url-адресами).
- Страницы с ошибкой 404 — если вы их не запретили, то поисковый бот может просканировать тысячи ненужных страниц.
- Низкокачественные и спамные страницы. Если вы знаете, что у вас на сайте есть подобные страницы, то их лучше запретить индексировать.
- Бесконечные страницы (простой пример — календарь. В нем может быть навигация по дням, неделям, месяцам, годам и т. д., и поисковый робот может просканировать тысячи ненужных страниц).
- Страницы поиска (например, если у вас есть несколько сотен материалов, то поисковые роботы могут начать индексировать все эти ненужные страницы с результатами поиска, что будет приводить к дублированию контента).
- Страницы корзины и оформления заказа. Это актуально исключительно для интернет-магазинов.
- Страницы с фильтрами, возможно даже страницы сравнения товаров — их может быть огромное количество (чем крупнее интернет-магазин, тем больше может существовать таких страниц) — от них нет никакой практической пользы, но все они по умолчанию индексируются поисковыми системами.
- Страницы с регистрацией и авторизацией. Их лучше запретить индексировать, потому что тем самым ваш сайт могут найти злоумышленники, для того чтобы попытаться его взломать.
- Версии для печати (если они существуют) содержат дублированный контент основного сайта, поэтому если у вас они есть, то их в обязательном порядке надо скрыть от индексации.
Естественно, что этот список ненужных страниц вы можете самостоятельно расширить, т. к. у вас на сайте, возможно, немного другая структура, и вы можете решить, что те или иные разделы поисковым роботам индексировать не нужно!
Выводы
Файл robots.txt – это важный инструмент управления доступом к страницам сайта для поисковых роботов. Он позволяет указать, какие страницы следует индексировать, а какие – нет. Создание и правильная настройка файла robots.txt помогает повысить эффективность индексации страниц и улучшить ранжирование сайта в поисковых результатах. При этом необходимо помнить, что этот файл не является способом защиты от злоумышленников или хакеров, и необходимо применять другие меры безопасности для защиты сайта.
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
 Старт
Старт  Стандарт
Стандарт  Премиум
Премиум 

